
1661 Average Time of Process per Machine: This is a really interesting question where we write a compact code of 1 line which is equivalent to multiline CTE code. Read more

Company: MAANG
Difficulty: Easy
Source: LeetCode
SQL Interview Question
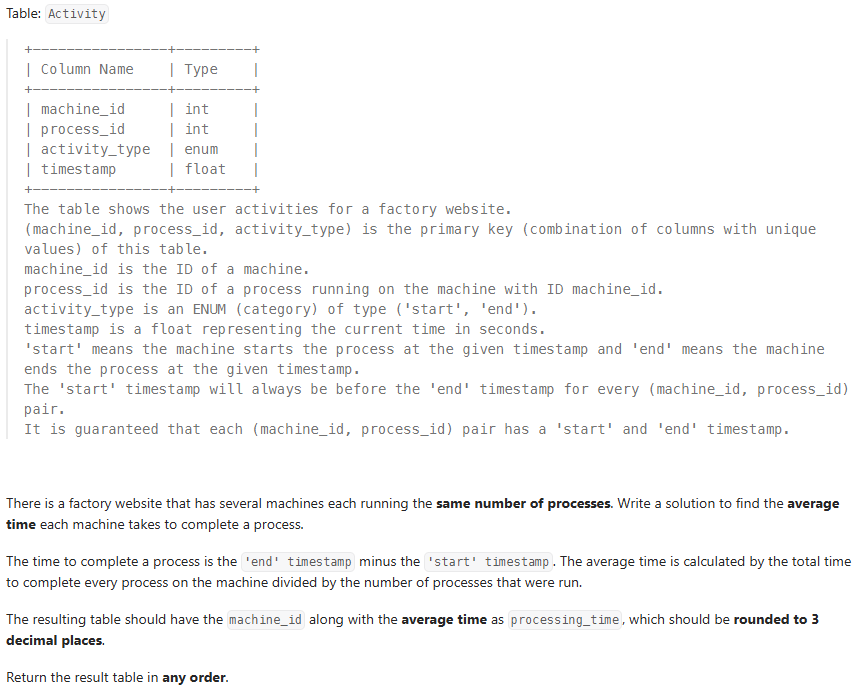
Q. 1661 Average Time of Process per Machine
CREATE TABLE Activity (
machine_id INT,
process_id INT,
activity_type TEXT CHECK(activity_type IN ('start', 'end')),
timestamp FLOAT
);
INSERT INTO Activity (machine_id, process_id, activity_type, timestamp) VALUES (0, 0, 'start', 0.712);
INSERT INTO Activity (machine_id, process_id, activity_type, timestamp) VALUES (0, 0, 'end', 1.52);
INSERT INTO Activity (machine_id, process_id, activity_type, timestamp) VALUES (0, 1, 'start', 3.14);
INSERT INTO Activity (machine_id, process_id, activity_type, timestamp) VALUES (0, 1, 'end', 4.12);
INSERT INTO Activity (machine_id, process_id, activity_type, timestamp) VALUES (1, 0, 'start', 0.55);
INSERT INTO Activity (machine_id, process_id, activity_type, timestamp) VALUES (1, 0, 'end', 1.55);
INSERT INTO Activity (machine_id, process_id, activity_type, timestamp) VALUES (1, 1, 'start', 0.43);
INSERT INTO Activity (machine_id, process_id, activity_type, timestamp) VALUES (1, 1, 'end', 1.42);
INSERT INTO Activity (machine_id, process_id, activity_type, timestamp) VALUES (2, 0, 'start', 4.1);
INSERT INTO Activity (machine_id, process_id, activity_type, timestamp) VALUES (2, 0, 'end', 4.512);
INSERT INTO Activity (machine_id, process_id, activity_type, timestamp) VALUES (2, 1, 'start', 2.5);
INSERT INTO Activity (machine_id, process_id, activity_type, timestamp) VALUES (2, 1, 'end', 5.0);View code on DB Fiddle
Solution
Solution1
WITH ProcessTimes AS (
SELECT
machine_id,
process_id,
MAX(CASE WHEN activity_type = 'end' THEN timestamp END) AS end_time,
MAX(CASE WHEN activity_type = 'start' THEN timestamp END) AS start_time
FROM Activity
GROUP BY machine_id, process_id
),
ProcessingDurations AS (
SELECT
machine_id,
(end_time - start_time) AS processing_time
FROM ProcessTimes
)
SELECT
machine_id,
ROUND(AVG(processing_time), 3) AS processing_time
FROM ProcessingDurations
GROUP BY machine_id
ORDER BY machine_id;Explanation
To solve this problem using the CTE (Common Table Expression) method, we’ve broken the process into three steps:
Step 1: Extracting Start and End Times (CTE: ProcessTimes)
The first thing we needed to do was transform the start and end timestamps from the row level to the column level for each machine_id and process_id. In the provided Activity table, the start and end times appear as separate rows for the same process_id. To perform calculations efficiently, these values need to appear in separate columns (start_time and end_time) for each process_id.
To achieve this, we used a CASE statement inside the first CTE (ProcessTimes):
- CASE Statement:
CASE
WHEN activity_type = 'start' THEN timestamp
ELSE NULL
ENDThis captures the timestamp for start and end rows.
Using MAX:
Wrapping the CASE statements in MAX allows us to satisfy SQL’s grouping rules when using GROUP BY on machine_id and process_id:
MAX(CASE WHEN activity_type = 'start' THEN timestamp END) AS start_time,
MAX(CASE WHEN activity_type = 'end' THEN timestamp END) AS end_time
Does MAX change the values? No, since the problem guarantees only one start and end timestamp per process_id. MAX simply ensures compliance with GROUP BY. If multiple values existed, MAX would pick the latest, which still works for duration calculations.
Resulting Output (ProcessTimes):
| machine_id | process_id | start_time | end_time |
| 0 | 0 | 0.712 | 1.520 |
| 0 | 0 | 3.140 | 4.120 |
| 1 | 0 | 0.550 | 1.550 |
Step 2: Calculating Process Duration (CTE: ProcessingDurations)
In this step, we calculate the duration of each process by subtracting the start_time from the end_time:
SELECT
machine_id,
(end_time - start_time) AS processing_time
FROM ProcessTimesThis creates a table (ProcessingDurations) where each row represents the duration of a single process for a specific machine. The result looks like this:
| machine_id | processing_time |
|---|---|
| 0 | 0.808 |
| 0 | 0.980 |
| 1 | 1.000 |
Step 3: Aggregating Average Processing Time
Finally, we calculate the average processing time for each machine. Using the results from ProcessingDurations, we calculate the average as follows:
SELECT
machine_id,
ROUND(AVG(processing_time), 3) AS processing_time
FROM ProcessingDurations
GROUP BY machine_id
ORDER BY machine_idAVG(processing_time): Calculates the average of all process durations for a machine.ROUND(..., 3): Rounds the result to 3 decimal places, as required by the problem.GROUP BY machine_id: Groups the results by each machine.
Final Output
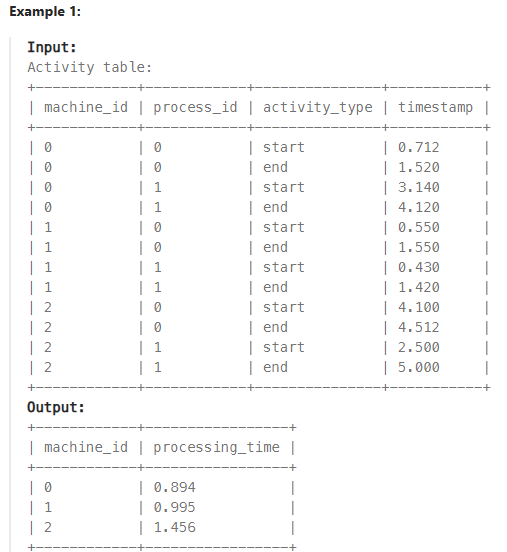
The query produces the following result:
| machine_id | processing_time |
|---|---|
| 0 | 0.894 |
| 1 | 0.995 |
| 2 | 1.456 |
This output satisfies the requirements of the problem.
Solution 2
SELECT
machine_id,
ROUND(SUM(CASE WHEN activity_type='start' THEN timestamp*-1 ELSE timestamp END)*1.0/ (SELECT COUNT(DISTINCT process_id)),3) AS processing_time
FROM
Activity
GROUP BY machine_idExplanation
For this solution you need to understand the below part, where entire three CTEs are in one line itself, using a mathmetical logic.
SUM(CASE WHEN activity_type='start' THEN timestamp*-1 ELSE timestamp END) * 1.0 / (SELECT COUNT(DISTINCT process_id))To understand this better let’s break it down further:
SUM(CASE WHEN activity_type=’start’ THEN timestamp*-1 ELSE timestamp END)
This part calculates the total time for each process. the logic used here is:
- If
activity_type = 'start':- The
timestampis multiplied by-1. This effectively turns thestarttime into a negative value so it can be subtracted later.
- The
- If
activity_type = 'end':- The
timestampis added as-is (positive).
- The
This means for every process, the start time and end time are combined to produce the processing duration. For example:
- For
start = 0.712andend = 1.52, this will sum to:
(−0.712)+1.52=0.808 (duration of the process)SUM: The SUM function adds up these values for all processes within the same machine (GROUP BY machine_id is applied in the query). This gives the total processing time for the machine.
1.0
This part ensures that the division produces a floating-point result instead of an integer.
- Without
* 1.0, SQL might perform integer division and truncate the decimal part, depending on the database. - Multiplying by
1.0ensures the calculation is performed in floating-point arithmetic, preserving the precision.
/ (SELECT COUNT(DISTINCT process_id))
This calculates the average processing time by dividing the total processing time (from step 1) by the number of unique processes for the machine.
Putting It All Together
SELECT
machine_id,
ROUND(SUM(CASE WHEN activity_type='start' THEN timestamp*-1 ELSE timestamp END)*1.0/ (SELECT COUNT(DISTINCT process_id)),3) AS processing_time
FROM
Activity
GROUP BY machine_idFinal Output
The query produces the following result:
| machine_id | processing_time |
|---|---|
| 0 | 0.894 |
| 1 | 0.995 |
| 2 | 1.456 |
I hope this would have been helpful for you, consider sharing it with your friends. thank you.
- Mastering Pivot Table in Python: A Comprehensive Guide
- Data Science Interview Questions Section 3: SQL, Data Warehousing, and General Analytics Concepts
- Data Science Interview Questions Section 2: 25 Questions Designed To Deepen Your Understanding
- Data Science Questions Section 1: Data Visualization & BI Tools (Power BI, Tableau, etc.)
- Optum Interview Questions: 30 Multiple Choice Questions (MCQs) with Answers
Hi, I am Vishal Jaiswal, I have about a decade of experience of working in MNCs like Genpact, Savista, Ingenious. Currently i am working in EXL as a senior quality analyst. Using my writing skills i want to share the experience i have gained and help as many as i can.